
")
As Kubernetes continues to gain popularity, knowledge of this container orchestration platform has become a sought-after skill in the tech industry. Whether you are a seasoned Kubernetes pro or just getting started, it is essential to know the answers to the following questions commonly asked in Kubernetes interview questions.
Top & Latest Kubernetes Interview Questions and Answers
If you’re preparing for a Kubernetes interview, you must have a solid understanding of the fundamental concepts and components of the platform. Here are 25 important Kubernetes interview questions and answers to help you prepare:
Basic Kubernetes Interview Questions for Freshers
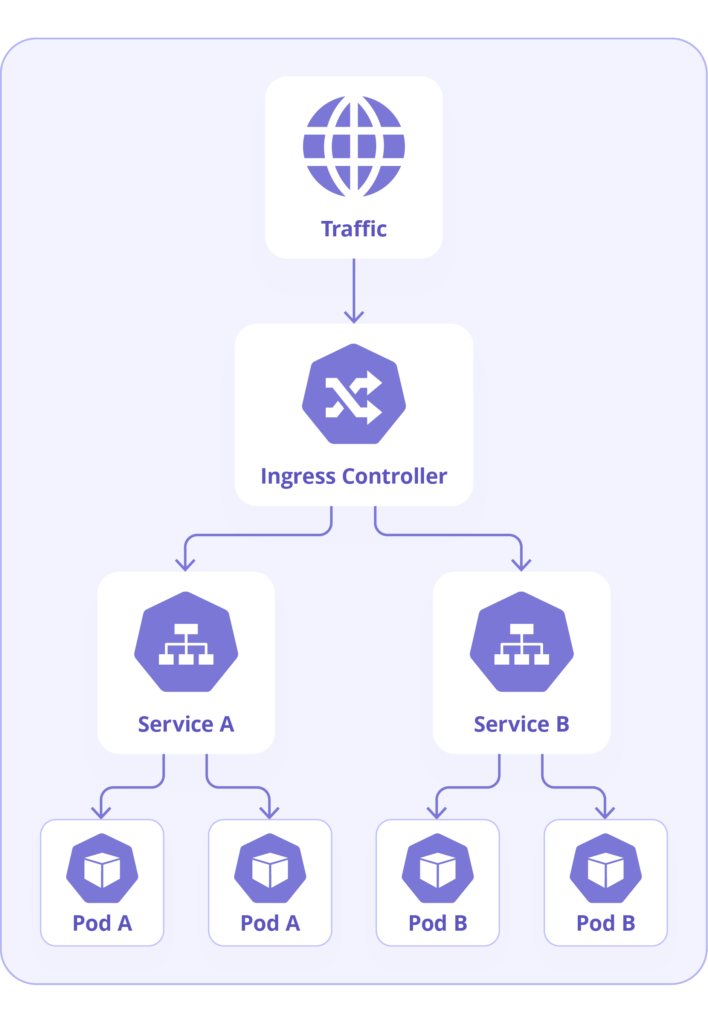
What is a Kubernetes ingress? How is it used?
A Kubernetes ingress is an API object that allows external traffic to be routed to the appropriate Kubernetes services based on the incoming request’s URL or host. It is used to expose HTTP and HTTPS routes to the Kubernetes cluster.
How do you handle secrets and configuration management in Kubernetes?
Kubernetes provides a built-in secret’s API resource for securely storing sensitive information such as passwords, API keys, and other confidential data. Kubernetes also allows for configuration management using config maps, which can be used to store non-sensitive configuration data as key-value pairs
Also Read, comprehensively about Kubernetes Secrets Security Issues.
How do you automate Kubernetes deployments?
Kubernetes deployments can be automated using various tools such as Helm, Kubernetes Operators, or GitOps workflows. Helm is a package manager for Kubernetes that allows users to define, install, and upgrade Kubernetes applications. While Kubernetes Operators are a Kubernetes-native way of automating application management, GitOps relies on Git as the source of truth for defining and deploying Kubernetes applications.
How do you scale Kubernetes applications horizontally and vertically?
Scaling Kubernetes applications can be done horizontally or vertically. Horizontal scaling involves adding more replicas of the application, while vertical scaling increases the resources of the individual pod. Kubernetes supports both types of scaling, and it can be easily achieved by modifying the replica count or resource limits of a deployment or Statefulset.
What is the difference between a Kubernetes namespace and a label?
A Kubernetes namespace is a way to divide cluster resources between multiple users or teams. It provides a way to isolate resources and prevent naming conflicts. On the other hand, Kubernetes labels are key-value pairs attached to Kubernetes objects to help identify and organize them.
How does Kubernetes handle load balancing and network traffic routing?
Kubernetes uses a Service object to handle load balancing and network traffic routing. A Service provides a single IP address and DNS name for a set of pods and routes traffic to those pods based on a set of rules defined by the user.
What is a Kubernetes secret, and how is it different from a Kubernetes configuration map?
A Kubernetes secret is an object used to store sensitive information, such as a password or API key. A configuration map, on the other hand, is used to store configuration data that a pod or container can consume.
How do you deploy a stateful application in Kubernetes?
Deploying a stateful application in Kubernetes requires using Statefulsets, which provides guarantees around the ordering and uniqueness of pod startup and termination.
What is the difference between a Kubernetes deployment and a Kubernetes Daemonset?
A Kubernetes deployment manages a set of identical replicas of a defined application instance. It ensures that the desired number of replicas are running and monitors their health. Deployments manage the creation, update, and scaling of pods, which are the basic units in Kubernetes.
On the other hand, a Kubernetes Daemonset ensures that all the nodes in a cluster run a copy of a specific pod. A Daemonset controller creates pods on each node in the cluster and then monitors them to ensure they are healthy. Daemonsets are helpful for deploying cluster-level applications such as log collectors and monitoring agents.
In summary, a Kubernetes deployment is used to manage multiple identical replica pods while a Kubernetes Daemonset is used to ensure that a specific pod runs on all nodes in a cluster.
Prepare for Practical Kubernetes interview Questions with Certified Cloud-Native Security Expert Course that provides hands-on lab-based training in Kubernetes and security
Helm Chart Kubernetes Interview Questions
Here is the Helm Chart Kubernetes Interview question that is commonly asked in Kubernetes’ latest nterviews:
What is a Kubernetes Helm Chart, and how can it help with application deployment?
A Kubernetes Helm Chart is a collection of Kubernetes manifest files packaged together in a single archive. Helm Charts can simplify application deployment and management by providing a standard way to package and version applications.
Kubernetes Advanced Interview Questions for 5 Years Experienced Professionals
For senior candidates with 5 years of experience and more, advanced and tough Kubernetes Interview Questions and answers are required and often involve challenging questions that assess not only their technical knowledge but also their problem-solving abilities and best practices.
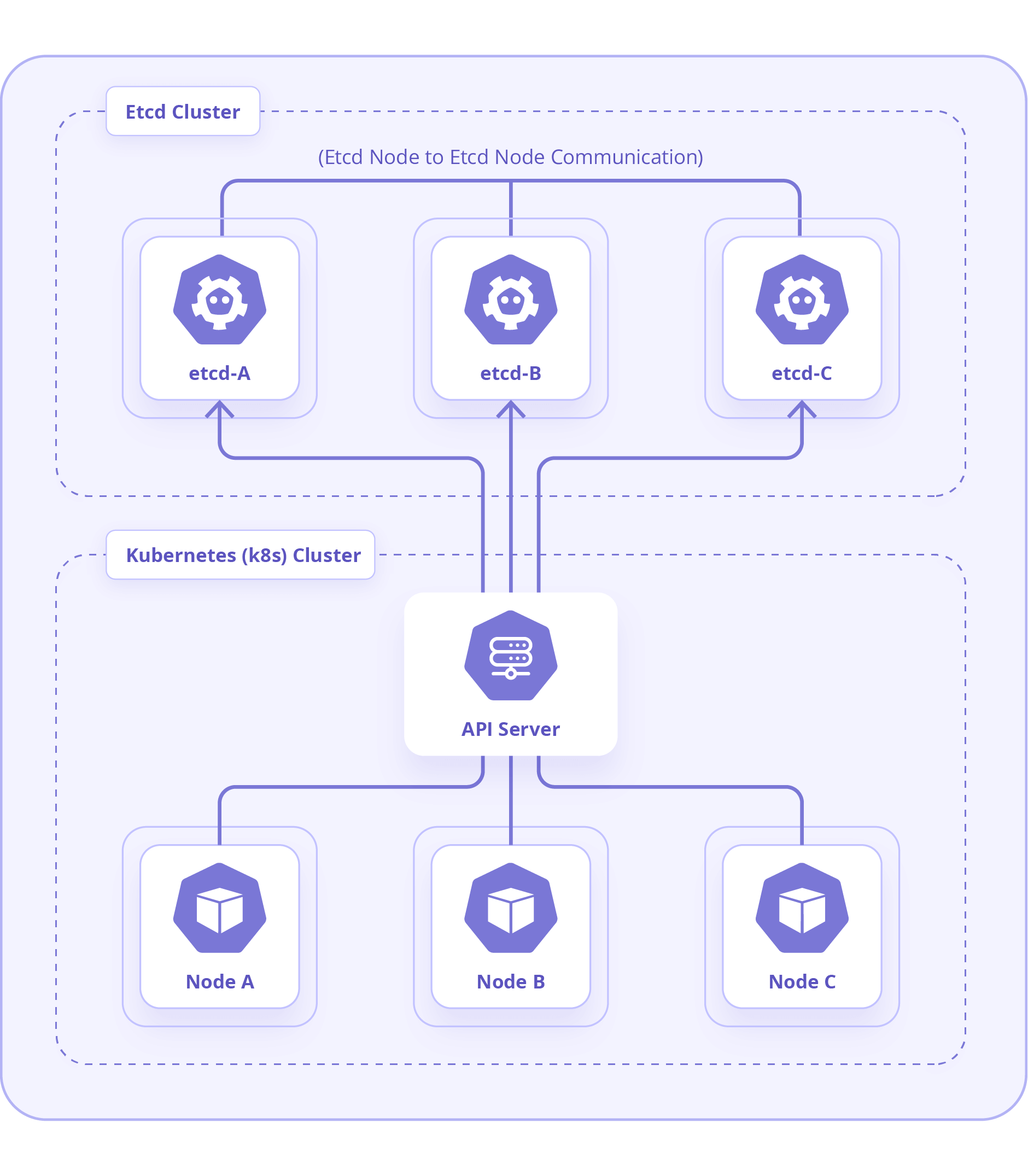
What is etcd, and what role does it play in a Kubernetes cluster?
Etcd is a distributed key-value store that stores the configuration data of a Kubernetes cluster. It is primarily used to store the state of the cluster and provides a reliable source of truth for cluster consistency. In a production environment, it is recommended to have an etcd cluster with a minimum of three nodes for high availability.
What is the difference between Kubernetes deployment and Kubernetes StatefulSets?
A Kubernetes deployment is suitable for stateless applications, while a Statefulset is ideal for stateful applications like databases. A deployment is designed to handle simple scaling and zero downtime rolling updates. In contrast, a Statefulset offers more guarantees on the ordering and uniqueness of pods and persistent storage.
What is a Kubernetes network policy? How does it work?
A Kubernetes network policy is a specification that defines how groups of pods can communicate with each other and with the outside world. It is used to enforce network traffic rules that restrict access to pods based on their labels or namespaces. Network policies use selectors and rules to allow or deny incoming or outgoing traffic between pods.
Also Read, comprehensively about Best Practices for Kubernetes Network Security.
Also Read, comprehensively about Kubernetes Pod Security Policies.
What is the difference between a Kubernetes Daemonset and a Kubernetes Statefulset?
Both Kubernetes Daemonsets and Statefulsets are used to manage pods, but they have different use cases. Daemonsets are used for running pods on every node in a cluster, while Statefulsets are used for deploying stable, ordered pods with unique network identities.
What is a Kubernetes custom resource? How does it work?
A Kubernetes custom resource is an extension of the Kubernetes API, providing a way to define and manage custom resources using Kubernetes-compliant tools and APIs. Custom resources can be used to manage applications and resources that are not native to Kubernetes.
What is a storage class in Kubernetes? How is it used?
A storage class is a Kubernetes object that defines the type of storage that can be used by a pod or a persistent volume claim (PVC). Storage classes are used to dynamically provision storage resources based on the requirements of the application.
What is a Kubernetes controller? Name a few different types of controllers.
A Kubernetes controller is a control loop that watches over a desired state of a Kubernetes object and takes action to ensure the current state matches the desired state. Some common types of controllers include ReplicaSet, Deployment, Statefulset, and Daemonset.
What is a Kubernetes deployment rollout strategy? Name a few different types of strategies.
A Kubernetes deployment rollout strategy is used to update a deployed application to a new version. Some common deployment strategies include RollingUpdate, Recreate, and Blue/Green.
What is a Kubernetes CRD (Custom Resource Definition), and how can you use it to extend Kubernetes functionality?
A Custom Resource Definition (CRD) is used to create new Kubernetes resources unavailable in the Kubernetes core. It is a way of extending Kubernetes functionality by defining custom resources that can be used to create Kubernetes objects, such as pods, services, and deployments.
Custom resources can represent any Kubernetes object type and can be used to create custom controllers that programmatically manage these resources. For example, you can create a CRD for a custom application load balancer and then use a custom controller to manage the load balancer.
In summary, a Kubernetes CRD allows you to create custom resources that extend Kubernetes functionality beyond its core features. You can use custom resources to create custom controllers that manage these resources programmatically.
Kubernetes Security Interview Questions
How does Kubernetes handle security and access control? What are some best practices for securing a Kubernetes cluster?
Kubernetes provides several built-in security features, such as role-based access control (RBAC), pod security policies, and network policies. Best practices for securing a Kubernetes cluster include applying security updates regularly, using strong authentication and access controls, and using network segmentation to separate resources.
Also, Read comprehensively about Best Kubernetes Authentication Methods
Also, Read comprehensively about Automating Security in Kubernetes Pipelines.
Also Read, Why Kubernetes Security is a Promising Career Choice
Other K8 Questions and Answers
How do you handle storage in Kubernetes? What are the various types of storage you can use?
Kubernetes provides several options for handling storage, including local storage, hostPath volumes, network-attached storage (NAS), and cloud-based storage. Each option has its pros and cons depending on the specific use case.
What is a Kubernetes Operator, and how is it used?
A Kubernetes Operator is a method for packaging, deploying, and managing Kubernetes-native applications. An Operator defines a set of custom resources and controllers to automate the management of complex applications.
Also Read, Best Books on Kubernetes Security
What is the role of a Kubernetes Service Mesh, and why would you use one?
A Service Mesh is a dedicated infrastructure layer designed to manage service-to-service communication within a Kubernetes cluster. Service Meshes provide authentication, authorization, and observability features for distributed systems.
What is a Kubernetes ConfigMap? How is it different from a Kubernetes Secret?
A Kubernetes ConfigMap is an object used to store configuration data that a pod or container can consume. On the other hand, a Kubernetes Secret is used to store sensitive information, such as a password or API key.
Also Read, Kubernetes Best Practices for Security
How do you manage resource requests and limits in Kubernetes?
Kubernetes provides several mechanisms for managing resource requests and limits, including Pod resource requests and limits, and the Kubernetes Horizontal Pod Autoscaler.
How do you manage resource requests and limits in Kubernetes?
Kubernetes provides several mechanisms for managing resource requests and limits, including Pod resource requests and limits, and the Kubernetes Horizontal Pod Autoscaler.
What are the main components of a Kubernetes cluster, and what are their functions?
The Kubernetes cluster has master nodes that manage the cluster and worker nodes that run the applications. Key components include the API server (processes and validates requests), etcd (stores cluster state), scheduler (assigns work to nodes), controller manager (oversees cluster state), kubelet (manages pod lifecycle on nodes), kube-proxy (handles network communication), and the container runtime (runs containers).
How does Kubernetes use namespaces to organize cluster resources?
Kubernetes uses namespaces to organize and isolate resources within the cluster, like segregating environments (development, testing, production) or teams. This allows for efficient resource management, access control, and simplifies service naming within the same physical cluster.
Can you explain the process of a rolling update in Kubernetes?
Rolling updates in Kubernetes replace old pods with new ones incrementally, maintaining service availability. Managed through deployments, this process ensures that a certain number of pods are always operational, allowing for a smooth transition between versions and enabling quick rollbacks if issues arise, thus minimizing downtime.
What are liveness and readiness probes in Kubernetes, and how are they used?
Liveness probes in Kubernetes check if an application inside a pod is running, restarting it if the check fails. Readiness probes determine if the application is ready to process requests, ensuring Kubernetes directs traffic only to pods ready for it. These probes help maintain application reliability and availability.
How does Kubernetes’ scheduler decide where to place pods?
The scheduler in Kubernetes assigns pods to nodes based on resource requirements, node policies, and scheduling constraints like affinity and anti-affinity. It evaluates the resource needs of each pod and finds a suitable node with sufficient capacity, optimizing resource utilization and fulfilling specific deployment requirements.
Explain the concept of pod affinity and anti-affinity in Kubernetes?
Pod affinity and anti-affinity in Kubernetes influence pod placement decisions, enhancing co-location or separation for workload optimization. Affinity rules attract pods to specific nodes, while anti-affinity repels them, enabling high availability, performance efficiency, and strategic distribution across the cluster.
How does Kubernetes handle persistent storage and dynamic provisioning?
Kubernetes handles persistent storage via Persistent Volumes (PVs) and Persistent Volume Claims (PVCs), supporting various storage backends. Dynamic provisioning automates PV creation in response to PVC requests, ensuring consistent and reliable storage allocation without manual intervention, facilitating stateful application management.
What is the role of RBAC (Role-Based Access Control) in Kubernetes?
Role-Based Access Control (RBAC) in Kubernetes manages user and process permissions, defining who can access which resources and operations. It uses roles to define permissions and bindings to assign those roles to users or groups, enhancing security by ensuring only authorized access to cluster resources.
How can you monitor and log applications in a Kubernetes environment?
Monitoring in Kubernetes tracks the health and performance of pods and nodes, using tools like Prometheus for metrics collection and Grafana for visualization. Logging captures and analyzes application and system logs, utilizing Elasticsearch, Fluentd, and Kibana for comprehensive log management, aiding in troubleshooting and operational insights.
How does Kubernetes’ Horizontal Pod Autoscaler (HPA) work, and when would you use it?
The Horizontal Pod Autoscaler (HPA) automatically adjusts the number of pod replicas in a deployment based on observed CPU utilization or other specified metrics. Used to maintain performance during varying load, HPA scales out (increases replicas) during high demand and scales in (reduces replicas) during low usage, optimizing resource use.
Describe the process of blue/green deployment in Kubernetes?
Blue/green deployment in Kubernetes involves running two identical environments (blue and green), only one of which serves live traffic at a time. This strategy enables testing in the green environment while the blue handles live traffic, switching traffic to green once it’s verified stable, reducing deployment risk and downtime.
What is a Pod Disruption Budget (PDB) in Kubernetes, and why is it important?
A Pod Disruption Budget (PDB) in Kubernetes ensures that a specified minimum number of pods remain running during voluntary disruptions like upgrades or maintenance. PDBs protect applications’ availability, preventing the system from evicting too many pods from a service, crucial for maintaining service reliability and availability during operational activities.
How does Kubernetes’ service discovery mechanism work?
Service discovery in Kubernetes automatically assigns a stable DNS name and IP address to each service, allowing other pods to discover and communicate with services reliably. This mechanism simplifies internal communication within the cluster, ensuring that services can easily locate and connect with each other regardless of node placement.
Explain the concept of Quality of Service (QoS) in Kubernetes and how it affects pod scheduling?
Kubernetes assigns Quality of Service (QoS) classes to pods (Guaranteed, Burstable, BestEffort) based on their resource requests and limits. QoS influences pod scheduling and eviction priorities, ensuring critical services get the necessary resources and maintain stable performance, while less critical pods can be adjusted or evicted based on cluster resource needs.
What is the significance of taints and tolerations in Kubernetes?
Taints and tolerations in Kubernetes control pod placement on nodes. Nodes can be tainted to reject certain pods unless those pods.
How can you ensure zero-downtime deployments in Kubernetes?
Zero-downtime deployments are achievable in Kubernetes using strategies like rolling updates, which gradually replace old pods with new ones, ensuring service availability. Properly configured readiness and liveness probes help manage the application state during deployment, avoiding downtime. Blue/green deployment and canary releases also contribute to maintaining availability by allowing testing of new versions alongside stable production versions before full rollout, minimizing the impact of potential errors.
Describe how you would troubleshoot a failing pod in Kubernetes?
To troubleshoot a failing pod in Kubernetes, start by inspecting the pod’s logs using kubectl logs for error messages or issues. Use kubectl describe pod to get more details about the pod’s state and events, identifying reasons for failure. Check resource limits, liveness and readiness probes, and network configurations for possible causes. Additionally, ensuring that the application code within the pod is debuggable and monitoring the pod’s metrics can provide insights into its behavior and potential issues.
What is the difference between imperative and declarative approaches in Kubernetes, and which do you prefer?
In Kubernetes, the imperative approach involves giving direct commands to perform actions on the cluster, like creating or updating resources manually. Declarative approach, however, involves defining the desired state of the cluster in configuration files and letting Kubernetes make changes to match that state. I prefer the declarative approach as it provides better scalability, version control, and easier rollback capabilities, aligning with Kubernetes’ design philosophy of declaring desired states for resources.
How do Kubernetes init containers differ from regular containers?
Init containers in Kubernetes are specialized containers that run before the main application containers in a pod. They are used to perform setup tasks such as preparing configurations, ensuring prerequisites are met, or waiting for external services to become available, ensuring the main containers start with the correct setup or dependencies. Unlike regular containers, init containers must complete successfully before the main application containers start, providing a sequenced, step-by-step initialization process.
Explain how Kubernetes supports multi-cloud and hybrid-cloud environments?
Kubernetes supports multi-cloud and hybrid-cloud environments by abstracting the underlying infrastructure, allowing the same cluster management and orchestration capabilities across different cloud providers and on-premises environments. This flexibility enables consistent deployment, scaling, and management of applications, regardless of the hosting environment. Kubernetes’ cluster federation extends its capabilities across cloud boundaries, enabling synchronized deployment, scaling, and management of services across various clouds and data centers, facilitating resilience, resource optimization, and geo-redundancy.
Kubernetes Deployment Questions
What are the different strategies for Kubernetes deployment, and when would you use each?
- RollingUpdate: Gradually replaces old pods with new ones, minimizing downtime. Ideal for most updates requiring high availability.
- Recreate: Terminates all old pods before new ones are created. Suitable for stateless applications where brief downtime is acceptable.
- Blue/Green: Deploys a new version alongside the old version, then switches traffic. Use it to test a new release in the production environment before going live.
- Canary: Introduces a new version to a small subset of users before rolling it out to everyone. Useful for testing the impact of changes incrementally.
How does Kubernetes handle zero-downtime deployments, and what are the key considerations for achieving them?
Kubernetes achieves zero-downtime deployments primarily through RollingUpdates and readiness probes that ensure traffic only goes to ready pods. Key considerations include proper health checks, resource allocation, and rollout strategy configuration.
Explain the process of a rolling update in Kubernetes and its benefits?
A rolling update gradually replaces pods of the previous version of an application with pods of the new version. This maintains service availability and allows rollback in case of issues, minimizing the impact on users.
What is a Pod Disruption Budget (PDB), and why is it important for Kubernetes deployments?
A PDB limits the number of pods of a replicated application that are down simultaneously from voluntary disruptions. This is crucial for maintaining high availability during maintenance and upgrades.
Describe the concept of blue/green deployment in Kubernetes and its advantages over traditional deployment methods?
Involves running two identical environments, one with the last version (blue) and one with the new version (green). Traffic is switched from blue to green once the new version is fully tested, reducing risk.
How can you ensure application scalability in Kubernetes deployments?
Ensure scalability by defining horizontal pod autoscalers, which adjust the number of pod replicas based on CPU usage or other metrics. Also, use resource requests and limits to manage the resource allocation efficiently.
What are liveness and readiness probes, and how do they contribute to deployment reliability in Kubernetes?
- Liveness probes: Check if the application is running. If it fails, Kubernetes restarts the pod.
- Readiness probes: Determine if the application is ready to handle traffic. Ensures traffic is only sent to pods that are ready.
Kubernetes Troubleshooting Questions
How would you troubleshoot a failing pod in Kubernetes, and what tools or commands would you use?
Use kubectl describe pod to check events and conditions. kubectl logs retrieves logs for debugging. Tools like Prometheus or K9s can provide deeper insights.
Explain the difference between imperative and declarative approaches in Kubernetes and their impact on troubleshooting?
- Imperative: Directly manage resources via commands. Quick fixes are possible, but it’s harder to maintain state consistency.
- Declarative: Define the desired state, and let Kubernetes handle changes. It’s more reproducible and easier to audit but can be complex to debug if the state drifts.
What are common challenges faced during Kubernetes deployments, and how can they be addressed?
Issues include image pull errors, resource limits, and security context problems. Address these by using proper tags, adequately setting limits, and ensuring correct permissions.
Describe best practices for monitoring and logging applications in a Kubernetes environment?
Implement centralized logging with tools like Fluentd or ELK stack. Use monitoring tools like Prometheus for metrics and Grafana for visualization to maintain the health of applications.
What strategies can be used to handle storage in Kubernetes, and how does storage management impact troubleshooting?
Use Persistent Volumes (PV) and Persistent Volume Claims (PVC) to manage storage independently of pod lifecycle. Proper storage management ensures data persistence across pod restarts and failures, simplifying troubleshooting related to stateful applications.
Kubernetes Interview Preparation Tips
Sure, here are some essential bullet points to help prepare for a Kubernetes interview:
- Understand Core Concepts: Be fluent with Pods, Deployments, Services, Nodes, and Namespaces.
- Networking Knowledge: Know how to configure and manage network policies, services, and ingress controllers.
- Storage Fundamentals: Understand Persistent Volumes, Persistent Volume Claims, and StorageClasses.
- Configuration Management: Be adept at using ConfigMaps and Secrets to configure applications.
- Logging and Monitoring: Familiarize yourself with tools like Prometheus for monitoring and Fluentd or ELK stack for logging.
- Security Practices: Know how to secure pods and clusters using Role-Based Access Control (RBAC), Network Policies, and Security Contexts.
- CLI Proficiency: Practice common `kubectl` commands for managing resources and debugging.
- High Availability: Understand concepts like ReplicaSets, Horizontal Pod Autoscaler, and Pod Disruption Budgets to ensure application availability.
- Troubleshooting Skills: Learn to identify and resolve issues with deployments, networking, and storage.
10.Update Mechanism: Know different deployment strategies such as Rolling Updates and Blue/Green deployments.
Conclusion
These are just ten of the many latest interview questions on Kubernetes questions you may face in an interview. To become a Kubernetes expert, it is fundamental to have a good grasp of the platform’s architecture, deployment strategies, and best practices. Our security certifications are an excellent way to deepen your understanding of Kubernetes and help you stand out in job interviews. Sign up today to get started!
How to Get Kubernetes Security Training?
You can get trained in Kubernetes security by enrolling in our Cloud-Native Security Expert (CCNSE) course, which provides hands-on training in important concepts such as
Hacking Kubernetes Cluster, Kubernetes Authentication and Authorization, Kubernetes Admission Controllers, Kubernetes Data Security, Kubernetes Network Security, Defending Kubernetes Cluster
Course Highlights:
- 50 + guided exercises uniquely designed by industry experts
- 24/7 instructor support
- Browser-based labs for hands-on training
- Lifetime access to course manuals and videos
Most Frequently Asked Questions
What are the most common challenges in managing Kubernetes clusters?
Common Challenges in Managing Kubernetes Clusters are Scalability issues, maintaining high availability, complex upgrades, and ensuring consistent security practices across the cluster.
How can you optimize the performance of a Kubernetes cluster?
Regularly update Kubernetes and its dependencies, use resource requests and limits wisely, and implement autoscaling.
What is the role of Kubernetes Admission Controllers?
They enforce governance and legal compliance by intercepting requests to the Kubernetes API server before object persistence but after authentication and authorization.
How do you manage multi-tenancy in Kubernetes?
Use namespaces for resource isolation, apply network policies for security, and set quotas to prevent resource hogging.
What are the key differences between Kubernetes and other container orchestration tools?
Kubernetes offers extensive automation, scalability, and community support compared to others, which may have simpler setups but less flexibility.
How do you handle Kubernetes version upgrades?
Plan carefully, test in a non-production environment first, and use tools like kubectl drain to prepare nodes for maintenance.
What is the importance of service discovery in Kubernetes?
It automates the detection of services and adjusts traffic routes as instances change, crucial for maintaining connectivity and uptime in dynamic environments.
How do you secure Kubernetes APIs?
Implement RBAC, use TLS for all API traffic, and keep APIs updated to mitigate vulnerabilities.
What are the best practices for monitoring Kubernetes clusters?
Utilize tools like Prometheus for monitoring and Grafana for visualization, set up alerts, and monitor cluster state and health regularly.
How do you handle logging in Kubernetes?
Implement centralized logging with Fluentd or ELK stack to aggregate logs from all nodes and pods, making it easier to analyze and troubleshoot.
Check out the Best DevSecOps certification course.
Download, Free E-books on Kubernetes Security.




0 Comments